
飞书作为一款高效远程办公软件,在疫情期间凭借着人性化的UI交互以及稳定的远程联络能力深得各大企业的偏好。但在创建团队之初,难免遇到需要批量导入数据或者批量处理员工信息的情况,飞书为此提供了各种API接口以便集中处理这些情况,此文的目的也是为了让各位团队管理者能自如使用这些API接口。
在了解飞书API接口前,我们先熟悉如何用python发送和接受请求,这里我是用的是requests模块。
POST请求方式
具体请求地址、Header、Body会在接口声明中提及,执行request.post()后会接收返回Body。1
2
3
4
5
6
7
8
9
10# 请求地址
url = "https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal/"
# 请求Header(字典形式储存)
header = {"content-type":"application/json",
"Authorization":"Bearer " + str(tat)}
# 请求Body(字典形式储存)
post_data = {"app_id":"xxx",
"app_secret":"xxx"}
# 发送POST请求
r = requests.post(url, data=post_data, headers=header)
GET请求方式
与POST请求方式大致相同,具体参数内容参见接口声明。1
2
3
4
5
6
7# 请求Header(字典形式储存)
header = {"content-type":"application/json",
"Authorization":"Bearer " + str(tat)}
# 请求地址
url = "https://open.feishu.cn/open-apis/contact/v1/tenant/custom_attr/get"
# 发送GET请求
r = requests.get(url, headers = header)
解析json
为便于对返回Body进行处理,我们通常将返回信息以json形式展示,方法如下:1
r.json()
这一部分建议大家查阅飞书API官方文档,以下两项为补充文档中未详细提及的部分
获取授权凭证
在使用API之前我们要先获得三种授权凭证,分别是:
app_access_token:访问App资源相关接口。tenant_access_token:访问企业资源相关接口。user_access_token:访问用户资源相关接口。
我们这里只介绍在企业管理中最常用到tenant_access_token的获取方式:
- 管理后台创建企业自建应用
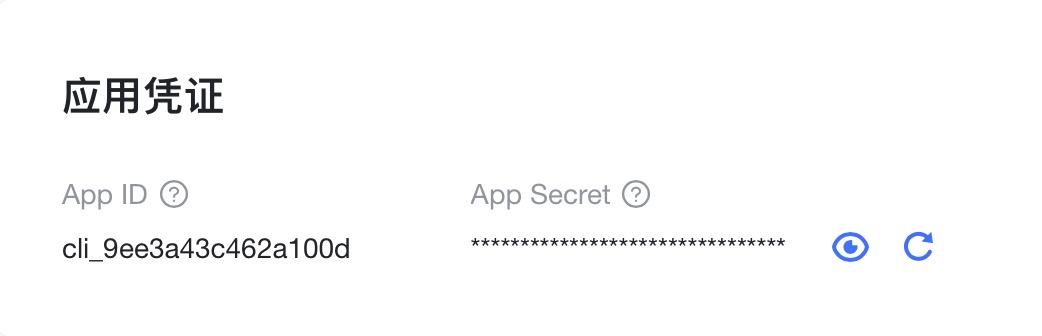
- 记录应用凭证内
AppID和AppSecret备用
- 从左侧三种应用功能任选一种
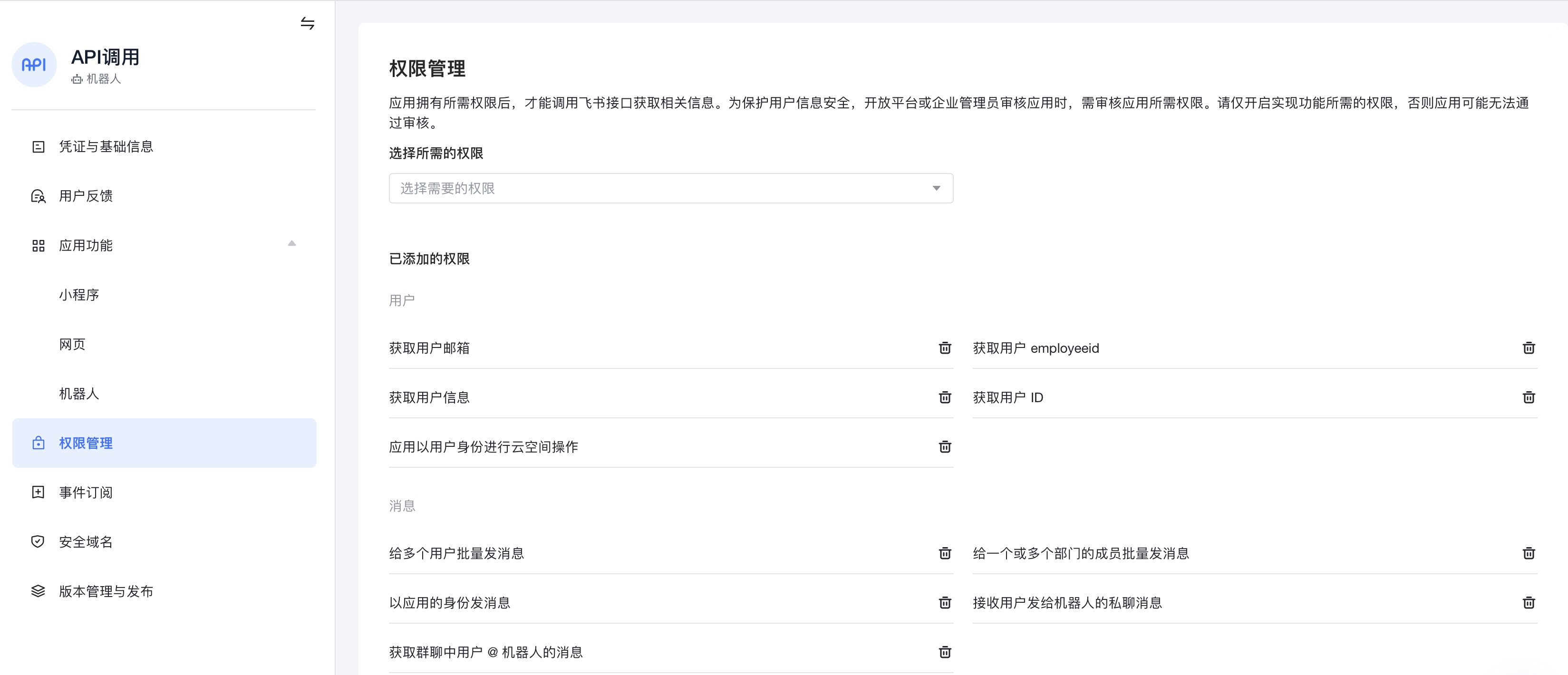
- 根据后续操作需要选择所需权限,具体权限内容参见这里
- 发布应用(应用于所有部门)
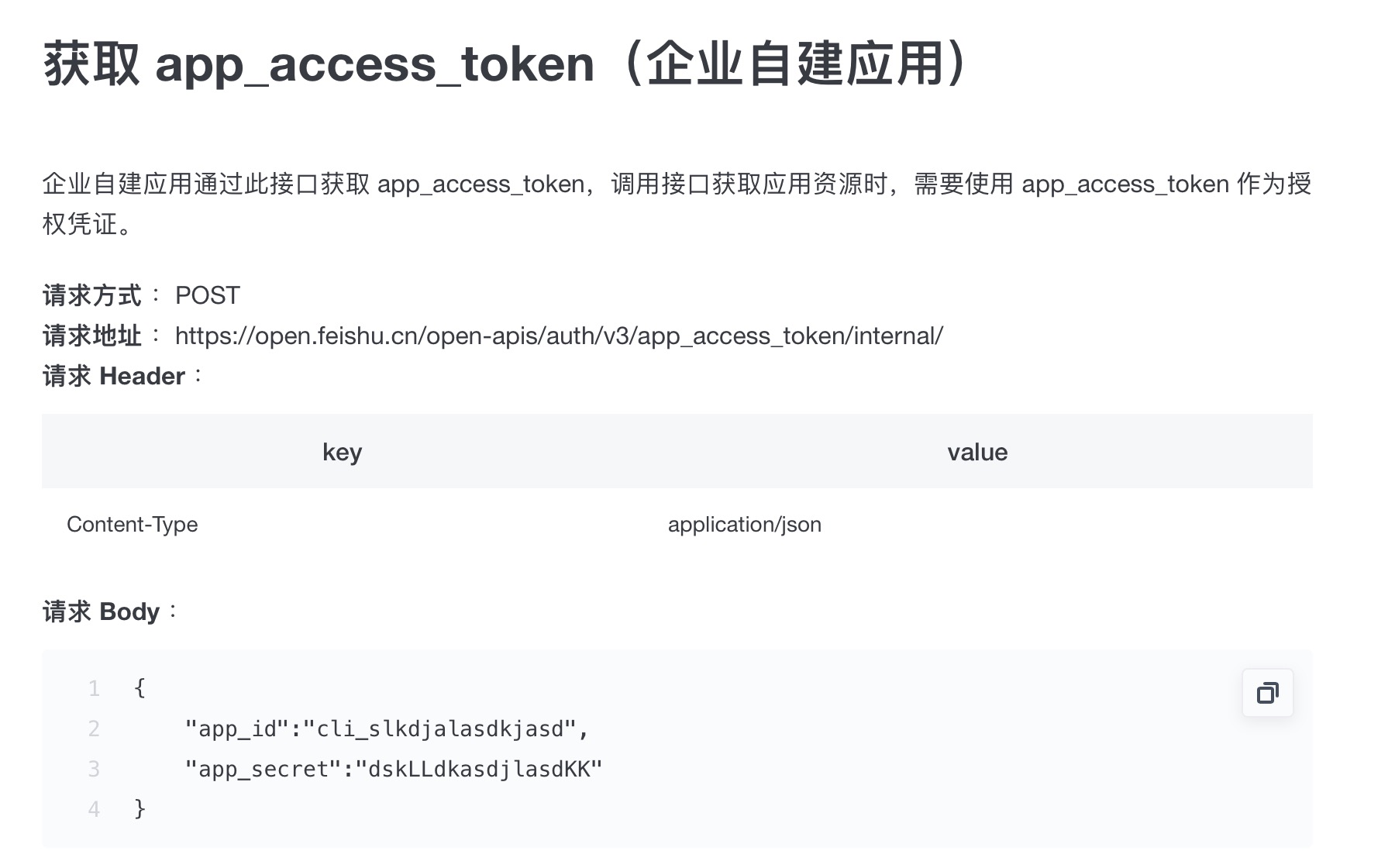
- 利用Request获取 app_access_token(企业自建应用)
明确API调用顺序
在这一部分我们以批量导入联系人为例(文末有python代码):
由于诸如部门id以及通讯录字段id等信息无法直接获得,我们在导入联系人前要先获得这些id信息
- 获取tenant_access_token
- 获取企业自定义用户属性配置
- 获取通讯录授权范围(所有部门id列表)
- 建立部门id与真实部门的键值对应关系
- 批量新增用户
因为在批量处理用户信息时我们所需要的基本都是从已有excel中读取相关信息,所以我们在这里只对pandas的读取功能做简要介绍。
import pandas as pd
导入pandas模块data = pd.read_csv( file, sep, encoding, nrows, skiprows)
data = pd.read_excel( file, sep, encoding, nrows, skiprows)
file为导入文件目录,sep为数据分隔符,nrows为读取前n行,skiprows为跳过某几行pd.DataFrame()
创建一个DataFrame对象data.head(3)/data.tail(3)
读取数据头/末3行data.iloc[]
提供基于整数的索引方式,索引序数而非标签data.to_numpy()
将pandas数组转化为np数组处理(对,有什么pandas数组不会的转成np数组操作岂不美汁汁)
1 | import json |